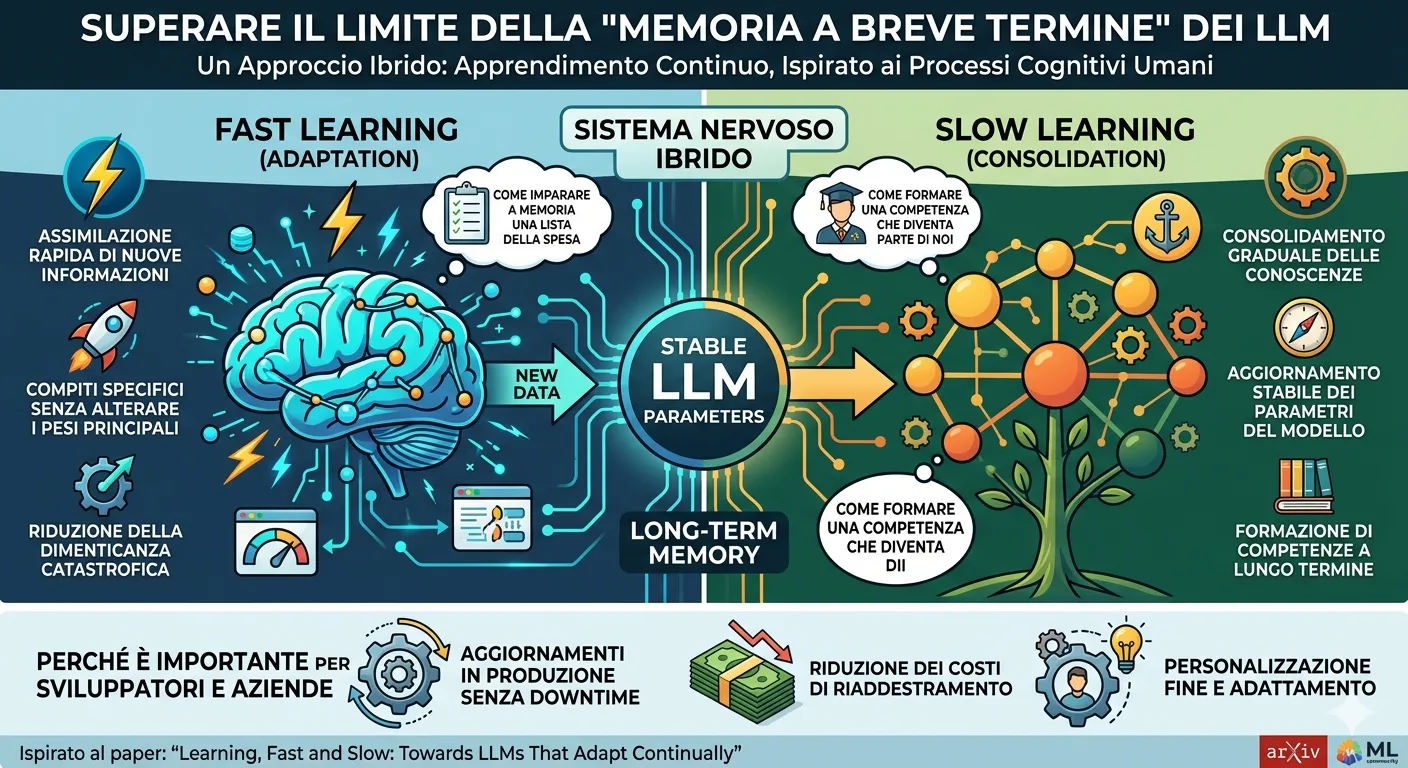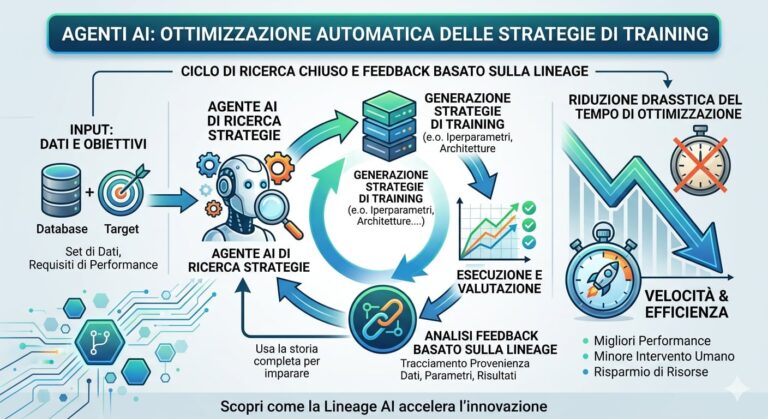
L’Auto-Ricerca guidata dagli Agenti: Come l’AI Impara a Ottimizzare i Modelli
Il vero collo di bottiglia nello sviluppo di modelli avanzati non è più solo la capacità di addestrare, ma la necessità di trovare la sequenza ottimale di esperimenti, modifiche di codice e configurazioni. Questo nuovo lavoro esplora come gli Agenti Specialisti possano affrontare questo problema, creando un ciclo di ricerca chiuso e empirico per scoprire le ‘ricette’ di training più efficaci.
Il problema che affrontiamo è: come possiamo ottimizzare parametri complessi (come le ‘recipe’ di training) senza dover ricorrere a un intervento umano costante e ingombrante? La risposta risiede nel creare un sistema che possa imparare dall’errore e dall’esperienza, proprio come farebbe un ingegnere esperto.
Il Ciclo di Ricerca Autonomo
La chiave di questa innovazione è l’istituzione di un ciclo di ricerca chiuso. Invece di lasciare che gli agenti generino suggerimenti isolati, qui li si organizza in modo che ogni tentativo (ogni ‘trial’) sia misurato da un valutatore esterno. Ogni tentativo include un’ipotesi, una modifica di codice eseguibile, un risultato e un feedback. Questo feedback non è solo un punteggio; è la linfa vitale che plasma la prossima mossa.
Gli agenti sono stati progettati per suddividere la superficie delle possibili ‘ricette’ di training e condividere la loro ‘lineage’ (la storia completa di come sono arrivati a quel risultato) tra di loro. Questo permette loro di capire non solo cosa ha funzionato, ma *perché* e *come* le modifiche di codice hanno influenzato il risultato finale.
Il Potere del Feedback basato sulla Lineage
La scoperta più significativa è che questa lineage feedback permette agli agenti di trasformare i risultati degli evaluator – inclusi crash, esaurimenti di budget o fallimenti di accuratezza – in modifiche dirette al livello del programma. Questo è un salto qualitativo rispetto ai metodi precedenti che offrivano solo suggerimenti uno-a-uno. Gli agenti possono ora correggere attivamente le ‘ricette’ di training, integrando le conoscenze acquisite in ogni ambiente di esperimento.
I risultati sono impressionanti: in 1.197 esperimenti e 600 controlli, il ciclo autonomo ha portato a miglioramenti tangibili. Ad esempio, sono stati ottenuti riduzioni significative nel tempo di validazione (bpb), aumenti nelle capacità dei modelli (come NanoChat-D12 CORE del 38.7%) e una riduzione del tempo di esecuzione per benchmark complessi (come CIFAR-10 Airbench96 del 4.59%).
Implicazioni per lo Sviluppo Software
Per gli sviluppatori e le aziende tech, questo significa che l’ottimizzazione dei workflow ML non deve essere un processo manuale e frammentato. L’adozione di loop di ricerca basati sull’evidenza permette di creare sistemi che non solo eseguono esperimenti, ma che imparano attivamente le migliori pratiche, riducendo drasticamente il tempo necessario per iterare su architetture complesse e per scoprire le configurazioni ottimali.
La ricerca dimostra che delegare la scoperta di parametri complessi a sistemi autonomi, guidati dal feedback misurato, è la prossima frontiera per l’ingegneria del Machine Learning.