Quando lavoriamo con i Large Language Model (LLM), il controllo del comportamento avviene quasi sempre tramite due leve principali:
- il prompt engineering,
- il fine-tuning / riaddestramento.
Entrambe hanno limiti evidenti: il prompt è fragile e poco deterministico, il fine-tuning è costoso, lento e poco reversibile. Negli ultimi mesi sta emergendo una terza via: lo steering delle attivazioni interne.
Lo steering permette di modificare il comportamento di un modello durante l’inferenza, intervenendo direttamente sulle sue rappresentazioni interne, senza toccare i pesi.
Cosa significa “steerare” un modello
Un transformer elabora il testo attraversando molti layer. In ciascun layer vengono prodotte delle attivazioni: vettori numerici ad alta dimensionalità che rappresentano in modo implicito concetti, relazioni semantiche, stile, intenzione.
L’idea chiave dello steering è semplice:
Se esiste una direzione nello spazio delle attivazioni associata a un certo comportamento o concetto, possiamo spingere il modello lungo quella direzione mentre genera testo.
Formalmente:xl→xl+α⋅v
dove:
- xl è l’attivazione del layer l,
- v è un vettore di steering,
- α è un coefficiente che controlla l’intensità dell’effetto.
Non si cambiano i pesi del modello: si modifica solo il flusso di attivazione in tempo reale.
Perché funziona
Gli LLM organizzano l’informazione in spazi latenti altamente strutturati. Molti concetti non sono memorizzati come simboli espliciti, ma come direzioni geometriche nello spazio vettoriale.
Questo significa che:
- certe direzioni corrispondono a stili,
- altre a temi,
- altre ancora a pattern di ragionamento o comportamento.
Applicando una piccola perturbazione controllata lungo una di queste direzioni, si può influenzare la generazione in modo consistente e ripetibile.
È un approccio più “interno” rispetto al prompt: invece di convincere il modello con parole, si agisce direttamente sulla sua rappresentazione numerica.
Come si ottiene un vettore di steering
Il vettore di steering non è casuale. Può essere estratto analizzando le attivazioni del modello tramite:
- raccolta di attivazioni associate a certi comportamenti,
- analisi statistica o decomposizioni (es. tecniche di feature extraction),
- strumenti di interpretabilità e analisi delle rappresentazioni interne.
Il risultato è una direzione che cattura una caratteristica semantica o comportamentale misurabile.
Una volta identificata, questa direzione può essere applicata dinamicamente durante l’inferenza.
Esempio concettuale (astratto)
Immagina lo spazio delle attivazioni come uno spazio multidimensionale:
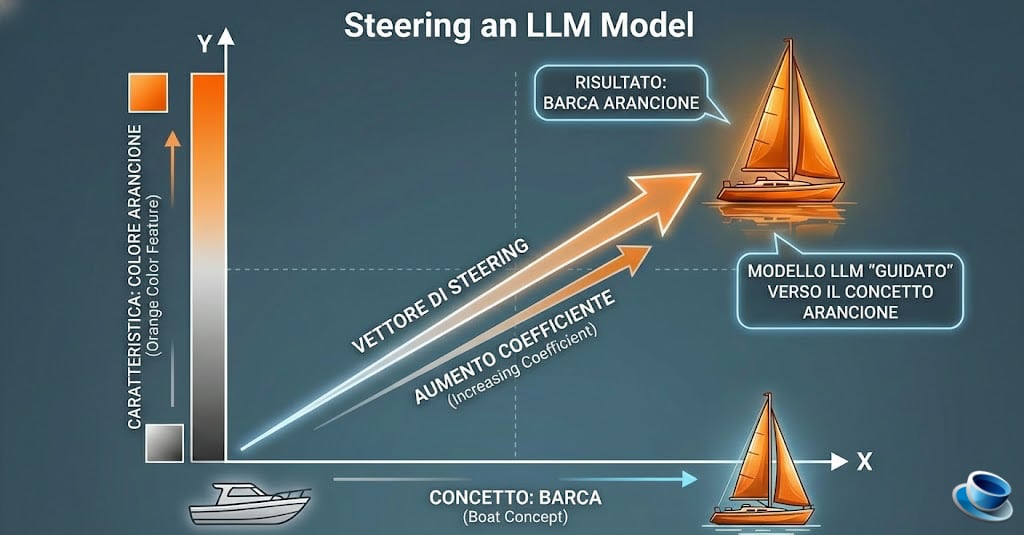
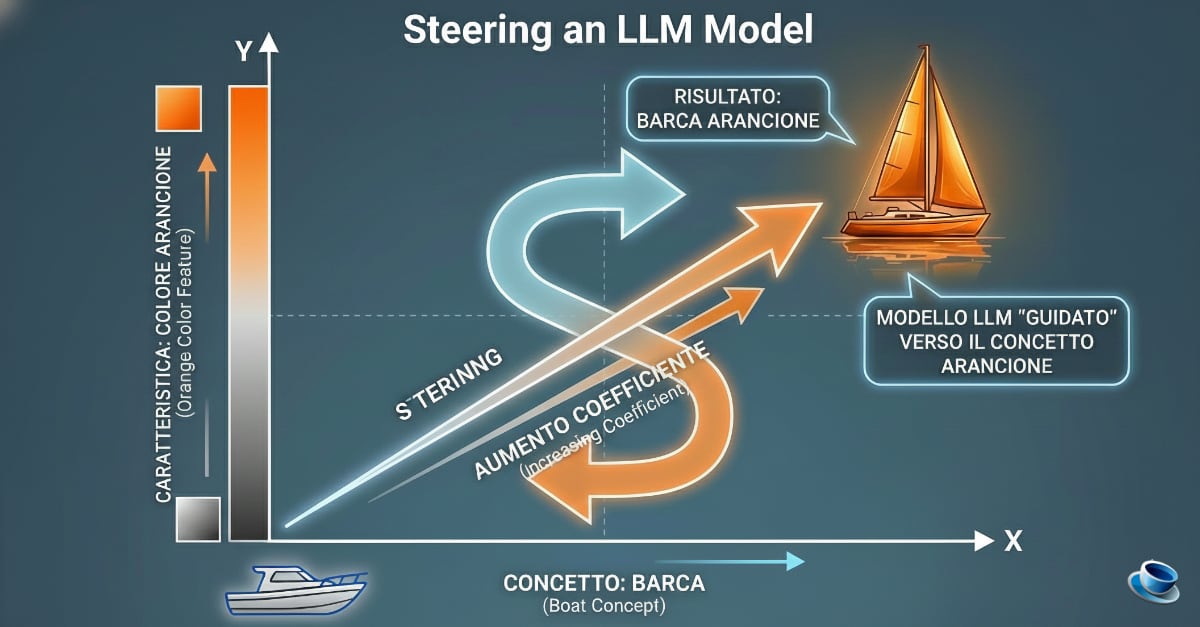
L’immagine è una metafora visiva di un processo tecnico chiamato “Activation Steering” (o guida delle attivazioni).
Ecco come funziona nella pratica all’interno di un modello linguistico:
Lo Spazio Latente (Il Piano Cartesiano)
Immagina che tutto ciò che l’IA conosce (parole, concetti, stili) sia disposto su una mappa multidimensionale chiamata spazio latente. In questa mappa, ogni punto rappresenta un’idea.
- Sull’asse delle X abbiamo posizionato il concetto puro di “Barca”.
- Sull’asse delle Y abbiamo isolato una caratteristica specifica: il colore “Arancione”.
Il Vettore di Steering (La Direzione)
Attraverso tecniche di interpretabilità (come quelle studiate da Anthropic con i “Golden Gate Claude”), i ricercatori possono identificare esattamente quale direzione nel “cervello” del modello corrisponde al concetto di arancione. Questo è il nostro Vettore di Steering. È come una bussola che dice al modello: “Qualunque cosa tu stia pensando, spostati un po’ più verso questa direzione”.
Il Coefficiente (L’Intensità)
Il coefficiente è la forza con cui spingiamo il modello in quella direzione:
- Coefficiente basso: La barca rimane grigia o con pochi riflessi. Il modello ignora quasi del tutto il suggerimento.
- Coefficiente bilanciato: La barca diventa arancione in modo naturale (come nell’immagine).
- Coefficiente troppo alto: Il modello potrebbe “impazzire”, iniziando a rispondere solo con la parola “arancione” o vedendo arancione ovunque, anche dove non dovrebbe esserci.
Perché è una tecnica interessante
Lo steering si posiziona tra prompt e fine-tuning:
| Approccio | Costo | Reversibilità | Controllo |
|---|---|---|---|
| Prompt | basso | alta | limitato |
| Fine-tuning | alto | bassa | alto |
| Steering | medio-basso | alta | medio-alto |
I vantaggi principali:
- non richiede riaddestramento,
- è applicabile a modelli già esistenti,
- è reversibile e sperimentabile rapidamente,
- permette un controllo più fine rispetto al solo testo di input.
Conclusione
Lo steering degli LLM dimostra che il comportamento di un modello non è solo una funzione del prompt o dei pesi, ma anche delle dinamiche interne delle sue rappresentazioni. Intervenire su queste dinamiche apre la strada a modelli più controllabili, interpretabili e adattabili, con un costo operativo molto inferiore rispetto al fine-tuning tradizionale.